
Modelos de clasificación basados en machine learning para la predicción de abandono de clientes en telecomunicaciones
Machine learning-based classification models for customer churn prediction in telecommunications
Merjory Grisell Candela Sevilla1
Filiación institucional
1 Universidad de San Martin de Porres, Lima, Perú.
RESUMEN
La pérdida de clientes es el desafío clave en la industria de las telecomunicaciones, un sector conocido por su intensa competencia y una dinámica de usuario cambiante. Los modelos de aprendizaje automático se han utilizado con éxito para predecir la deserción y mejorar los enfoques de retención. Este trabajo presenta una revisión bibliométrica y un análisis cienciométrico de estudios publicados durante 2020 y 2025 que implementan modelos de clasificación para predecir la deserción en campañas de retención de centros de llamadas. Se aplicó la metodología PRISMA, y la búsqueda literaria abarcó las bases de datos Scopus, IEEE Xplore, arXiv y ScienceDirect. Los contenidos de los datos fueron procesados utilizando Google Colab y Python para descubrir tendencias, autores involucrados en el análisis y algoritmos influyentes. Los resultados indicaron que Random Forest, XGBoost y Redes Neuronales fueron los enfoques más utilizados, con desempeños superiores al 90 %, y la inteligencia artificial explicable se utilizó cada vez más para mejorar la transparencia del modelo. En resumen, los enfoques de aprendizaje automático funcionan mejor que los métodos tradicionales, pero aún quedan algunos desafíos para la estandarización de métricas y aplicaciones realistas.
Palabras clave: customer churn prediction; customer retention; machine learning; telecommunications; classification models.
ABSTRACT
Customer loss is the key challenge in the telecommunications industry, a sector known for its intense competition and a changing user dynamic. Machine learning models have been successfully used to predict churn and improve retention approaches. This work presents a bibliometric review and a scientometric analysis of studies published during 2020 and 2025 that implement classification models to predict churn in call center retention campaigns. The PRISMA methodology was applied, and the literature search covered the Scopus, IEEE Xplore, arXiv, and ScienceDirect databases. The data contents were processed using Google Colab and Python to discover trends, authors involved in the analysis, and influential algorithms. The results indicated that Random Forest, XGBoost, and Neural Networks were the most used approaches, with performances above 90 %, and explainable artificial intelligence was increasingly used to improve model transparency. In summary, machine learning approaches perform better than traditional methods, but some challenges remain for metric standardization and realistic applications.
Keywords: predicción de abandono de clientes; retención de clientes; aprendizaje automático; telecomunicaciones; modelos de clasificación.
Recibido: 15-04-2025
Aprobado: 20-06-2025
Publicado: 09-07-2025
Citar como: Candela Sevilla, M. G. (2025). Modelos de clasificación basados en machine learning para la predicción de abandono de clientes en telecomunicaciones. Revista Peruana de Ingeniería, Arquitectura y Medio Ambiente, 2(2). https://doi.org/10.37711/ repiama.2025.2.2.4
Introducción
Considerando el panorama digital actual, el sector de las telecomunicaciones está experimentando una rápida evolución gracias al uso de tecnología altamente sofisticada basada en datos que se centra en la experiencia del cliente para maximizar la eficiencia operativa (Ouf et al., 2024; Sana et al., 2024). La retención de usuarios es ahora una de las consideraciones estratégicas críticas, teniendo en cuenta que el coste puede ser muchas veces más caro al adquirir un nuevo cliente que retener a los existentes (Subramanian et al., 2025). Como tal, los modelos de aprendizaje automático han surgido como tecnologías fundamentales capaces de analizar tendencias de comportamiento de los usuarios, identificar patrones de abandono y desarrollar tácticas de lealtad (Reddy et al., 2025; Liu et al., 2024).
Aunque ha habido un reciente aumento en los estudios sobre la predicción de abandono, los datos siguen fragmentados en términos de efectividad comparativa en cuanto a los algoritmos de clasificación aplicados (métricas de rendimiento) y si estos algoritmos son aplicables o no al contexto de campañas de retención del mundo real que se ejecutan en centros de llamadas (Ribeiro et al., 2024; Haddadi et al., 2024). Hay evidencia limitada sobre una comparación de métodos de segmentación tradicionales o métodos analíticos descriptivos con métodos basados en machine learning en muchos artículos (Zdanavičiūtė et al., 2022). Con este fin, también hay poco acuerdo en torno a los estándares de evaluación, como, por ejemplo, la precisión, el AUC y la puntuación F1, que no permiten una estandarización de los resultados (Freire et al., 2024; Moradi et al., 2024).
Esta revisión busca responder las siguientes preguntas de investigación:
• ¿Qué metodologías de análisis de datos se emplean para identificar las variables más relevantes en
campañas de retención de clientes de telecomunicaciones?
• ¿Qué algoritmos de clasificación basados en machine learning se utilizan con mayor frecuencia y cuáles muestran mejor desempeño en la predicción de churn (pérdida o rotación de clientes) en telecomunicaciones?
• ¿Qué tecnologías de machine learning se utilizan para implementar modelos de predicción de pérdida de
clientes y cómo contribuyen a mejorar la eficiencia en la toma de decisiones en campañas de retención?
Esta revisión proporcionará una visión de la tendencia predominante en la implementación de modelos de machine learningen la predicción de abandono, mapeando las brechas metodológicas actuales e identificando técnicas efectivas para su uso práctico. Además, el estudio proporcionará ideas que ayuden al desarrollo de marcos de retención más eficientes que requieran decisiones consideradas y duraderas, lo cual mejorará la capacidad de las empresas de telecomunicaciones para analizar información. El artículo se organiza de la siguiente manera: la sección 2 describe la metodología de búsqueda, la sección 3 detalla los resultados del análisis cienciométrico y la revisión bibliométrica, la sección 4 discute las implicaciones y limitaciones, y la sección 5 presenta las conclusiones y futuras líneas de investigación.
Metodos
La metodología para esta investigación utiliza el método mixto, que combina el análisis cienciométrico (Donthu et al., 2021) y permite realizar un examen bibliométrico de la producción científica en torno a un campo de estudio, identificando tendencias, autores, instituciones y revistas más influyentes relacionados con los modelos de clasificación basados en machine learning para la predicción de churn en clientes de telecomunicaciones a partir de datos de campañas de retención en call centers (centro de llamadas) (Aria & Cuccurullo, 2016). Para el análisis bibliométrico, se ha usado Excel, Google Colab y ChatGPT (Salgado-García et al., 2025). Mientras que la revisión bibliométrica (Kolaski et al., 2023) permite identificar, evaluar y sintetizar toda la evidencia disponible sobre una pregunta o tema de investigación específico. Su propósito es minimizar el sesgo y mejorar la precisión de las conclusiones, mediante la aplicación de procedimientos explícitos que incluyen la búsqueda exhaustiva, la selección basada en criterios definidos, la evaluación de la calidad de los estudios y el análisis crítico de los resultados. Esta investigación está basada en el marco conceptual PICO, entendido como una herramienta metodológica que guía la formulación de preguntas de investigación a través de la definición explícita de la población, la intervención, la comparación y los resultados, lo cual garantiza claridad y rigor en el proceso de revisión (Chocobar Reyes y Barreda Medina, 2025), y el protocolo de revisión sistemática OSF (Bradshaw et al., 2017), el cual consiste en diez etapas principales que guían el desarrollo de revisiones sistemáticas rigurosas, desde la formulación de la pregunta de investigación y la definición de palabras clave hasta la ejecución de búsquedas, la aplicación de criterios de inclusión/exclusión, la extracción de datos, el análisis y la redacción del informe final (ver Tabla 1). Para la escritura se usó la metodología PRISMA, la cual proporciona un conjunto estandarizado de directrices para estructurar, reportar y transparentar revisiones sistemáticas de manera rigurosa (Page et al., 2021). La autora propone todas las etapas de manera secuencial, para comprender el alcance actual de los modelos de clasificación basados en machine learning aplicados a la predicción de churn en clientes del sector de telecomunicaciones (Freire et al., 2024). Los datos se recopilaron de Scopus como la principal base de datos académica, complementada con otras fuentes digitales: arXiv (repositorio de preprints), IEEE Xplore (biblioteca digital especializada) y ScienceDirect (biblioteca digital editorial). Para evitar la duplicidad de artículos entre plataformas, se aplicaron filtros de depuración. Se han utilizado palabras clave específicas para las variables (V1: Machine learning classification models, V2: Customer churn prediction, V3: Call center retention campaign data in telecommunications) y un marco temporal de cinco años. Se identificaron setenta artículos, se eliminaron los duplicados y los sesenta documentos restantes se importaron a Zotero y se analizaron utilizando los softwares Excel y Google Colab. El análisis incluye la coocurrencia de palabras clave, la autoría, las cuidades, los países, la tecnología, los métodos, las citas y las fuentes para comprender la relación de la red de autores.
Selección de la base de datos y recopilación de datos
Esta revisión utilizó Scopus como la principal base de datos para la recopilación de información, debido a su amplia cobertura de publicaciones científicas revisadas por pares y su capacidad para proporcionar métricas bibliométricas confiables relacionadas con los modelos de clasificación basados en machine learning aplicados a la predicción de churn en clientes del sector de telecomunicaciones.
Asimismo, se complementó la búsqueda con otras bases de datos especializadas, como IEEE Xplore, ScienceDirect y arXiv, con el fin de ampliar el alcance de la revisión e incluir tanto estudios primarios como revisiones recientes relevantes.
Estas plataformas fueron seleccionadas por su reconocida reputación académica, el acceso a artículos en texto completo y su enfoque en investigaciones tecnológicas y de inteligencia artificial, aspectos fundamentales para el presente estudio.
Estrategia de selección de palabras clave, criterio de inclusión y exclusión
Para esta investigación, se realizó inicialmente una búsqueda exploratoria en Google Académico con el propósito de identificar artículos publicados en los últimos cinco años relacionados con la predicción de churn en el sector de telecomunicaciones mediante modelos de machine learning.
Los resultados obtenidos fueron filtrados y organizados en el gestor de referencias Zotero, donde se procedió a una lectura preliminar de los artículos con el fin de analizar las palabras clave más recurrentes dentro de los resúmenes, títulos y secciones metodológicas, como se presenta en la Figura 2. A partir de este análisis, se seleccionaron las palabras clave definitivas que conformaron las cadenas booleanas de búsqueda empleadas
posteriormente. La primera cadena de búsqueda dio como resultado 645 artículos después de aplicar los criterios de inclusión y exclusión. La segunda cadena de búsqueda dio como resultado diecinueve artículos. Los criterios de inclusión y exclusión incluyeron trabajos de ciencias ambientales, ingeniería, ciencias de la computación y energía publicados en los últimos cinco años, desde 2020 hasta octubre de 2025, escritos en inglés y convertidos en español con la herramienta de Google Traductor.
(“telecommunication sector” OR “telecom industry” OR “telecom services”) AND (“customer churn” OR “churn prediction” OR “customer retention”) AND (“classification models” OR “data analytics”)
Selección de herramientas informáticas para el análisis y la revisión del análisis sistemático
Para el desarrollo de la presente investigación, se utilizó un análisis cienciométrico fundamentado principalmente en la base de datos Scopus, complementado con información proveniente de arXiv, IEEE Xplore y ScienceDirect.
El procesamiento y el análisis de los datos bibliográficos se realizaron mediante Google Colab, aprovechando la biblioteca de Python para mapear la estructura, los patrones y la agrupación temática del dominio científico (Salgado-García et al., 2025), relacionado con la predicción de churn en telecomunicaciones mediante machine learning.
Los datos recopilados fueron depurados para eliminar duplicados y posteriormente analizados para generar redes de coocurrencia de palabras clave, coautoría, citación de documentos, países e instituciones.
El análisis de coocurrencia de palabras clave permitió identificar los conceptos y modelos más empleados por
los investigadores, así como detectar brechas temáticas y tendencias emergentes dentro del campo de estudio.
Etapas adoptadas en la revisión
En esta sección se analizan los elementos de informe preferidos para las revisiones bibliográficas y el modelo PRISMA, los cuales guían el proceso de revisión para garantizar transparencia, exhaustividad y reproducibilidad
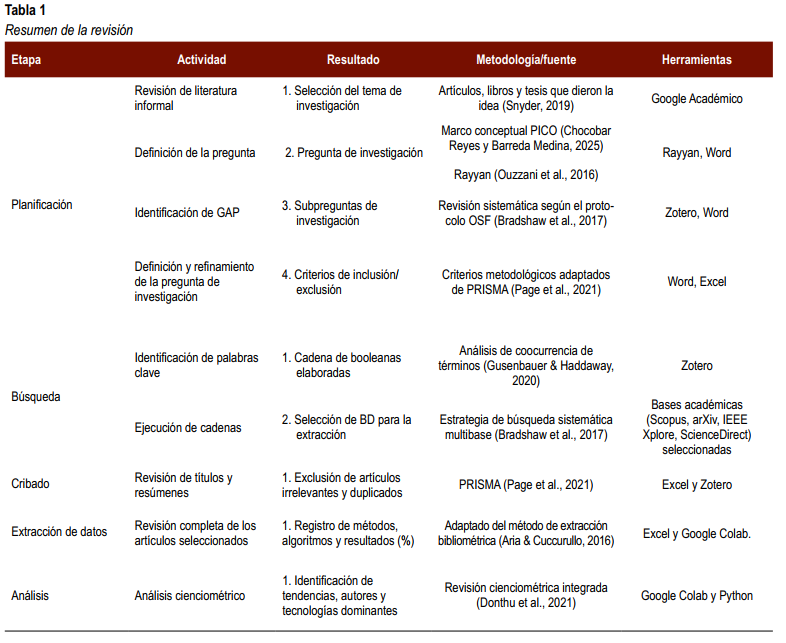
El flujo de revisión sistemática del presente estudio sigue las fases propuestas por el modelo PRISMA: identificación, cribado, elegibilidad e inclusión, las cuales estructuran el marco metodológico de la revisión.
La Figura 1 muestra el proceso de extracción de archivos de las bases de datos seleccionadas, como Scopus, IEEE Xplore, arXiv y ScienceDirect, donde se eliminaron duplicados y registros no pertinentes a los criterios definidos.
Resultados
Resultados de la búsqueda
Tras aplicar el protocolo PRISMA y los criterios de inclusión y exclusión establecidos, se recuperaron sesenta artículos publicados entre 2020 y 2025 de las bases de datos Scopus, IEEE Xplore, ScienceDirect y arXiv.
La revisión permitió identificar las principales tendencias en el uso de modelos de aprendizaje automático para predecir la pérdida de clientes en el sector de las telecomunicaciones.
Tendencias cronológicas y temáticas
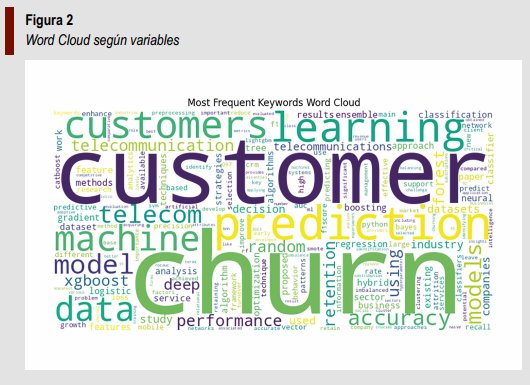
Según la Figura 3, la producción científica creció gradualmente desde 2020 y alcanzó su punto máximo en 2024, con más de treinta publicaciones. Este aumento refleja un interés creciente en las aplicaciones tecnológicas en telecomunicaciones, especialmente sus implicaciones para el uso de IA y el análisis predictivo en la gestión de clientes.
Los resúmenes y palabras clave de los artículos tienen los siguientes temas comunes:
a) Predicción de customer churn mediante algoritmos de machine learning y deep learning.
b) Uso de técnicas de balanceo de datos, como SMOTE y ADASYN, para manejar conjuntos desbalanceados.
c) Integración de modelos explicables (XAI) para la interpretabilidad de los resultados.
d) Aplicación de plataformas basadas en Python.
Estos resultados muestran que el enfoque más reciente dentro de la literatura ha sido mejorar el rendimiento de los modelos y la aplicación de sistemas predictivos a condiciones empresariales del mundo real.
Resultados del análisis cienciométrico
El análisis cienciométrico se desarrolló en Google Colab utilizando los datos extraídos de las bases Scopus, IEEE Xplore, ScienceDirect y arXiv, con un total de sesenta artículos comprendidos entre 2020 y 2025. Se aplicaron métricas de productividad, citación, métodos de aprendizaje automático y coocurrencia de palabras clave para identificar las principales tendencias de investigación.
Productividad y citación por país
La Figura 4 muestra la distribución global de citas por país. Los resultados evidencian que Islandia, Siria y Australia concentran la mayor cantidad de citas, superando las trescientas en promedio, seguidos por Baréin y el Reino Unido.
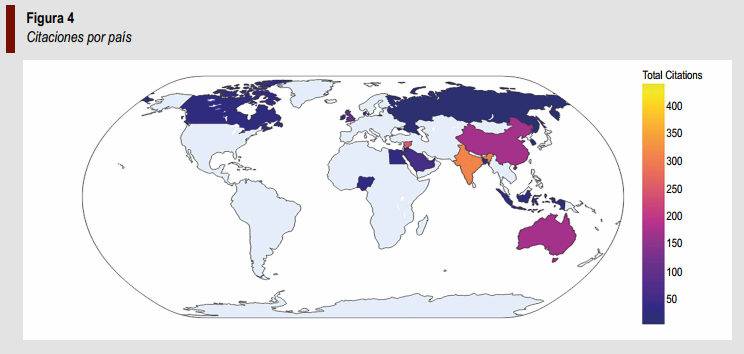
Estos países destacan por su inversión en investigación aplicada a la predicción de churn mediante técnicas de machine learning, por lo que se confirma su liderazgo en el campo, a diferencia de Latinoamérica, que presenta una baja contribución, con escasa producción científica relacionada con el tema (ver Tabla 2).

Métodos más utilizados
La Figura 5A y la Figura 5B ilustran los métodos más empleados en los estudios analizados.
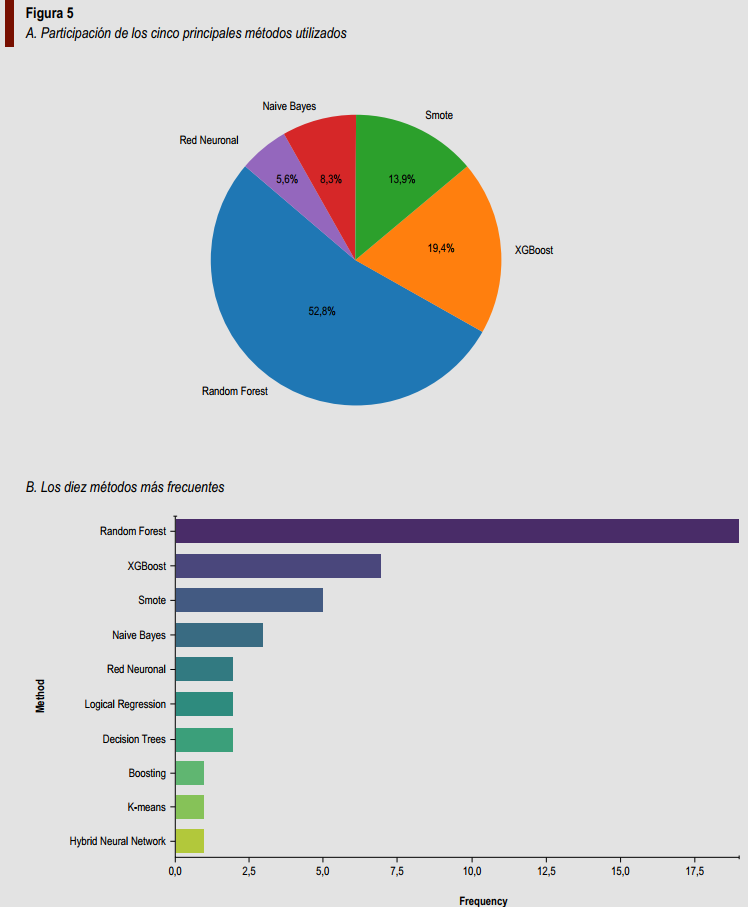
El Random Forest se posicionó como el modelo dominante con un 52,8 % de uso, seguido de XGBoost con 19,4 %, SMOTE al 13,9 %, Naive Bayes con 8,3 % y Red Neuronal con un 5,6 %.
Estos resultados confirman la preferencia de los investigadores por los modelos de ensemble learning, los cuales ofrecen un mejor rendimiento frente a datos desbalanceados.
Coocurrencia de palabras clave
El análisis de redes de coocurrencia (ver Figura 6) revela las relaciones conceptuales entre los términos más frecuentes en la literatura.
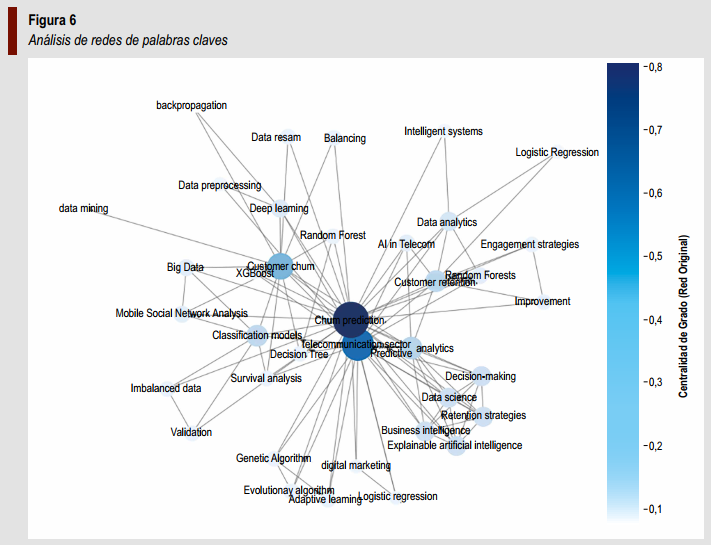
Los nodos con mayor centralidad son “Churn prediction”, “Telecommunication Sector”, “Customer retention” y “Customer churn”, lo que indica una fuerte interconexión entre la analítica predictiva y las estrategias de fidelización.
Discusión
Al analizar las variables de la revisión bibliométrica, permite entender de forma más completa de los modelos de clasificación basados en aprendizaje automático que se están haciendo al predecir la pérdida de clientes utilizando datos de campañas de retención de centros de llamadas de telecomunicaciones. Los hallazgos de los sesenta artículos revisados muestran que la mayoría de los estudios aplican algoritmos de aprendizaje supervisado debido a sus superiores capacidades predictivas en conjuntos de datos altamente complejos y desbalanceados. Específicamente, los modelos de conjunto como Random Forest y XGBoost logran bandas de precisión de entre 0,85 y 0,99, superando a los modelos lineales clásicos. Este hallazgo se alinea con la investigación publicada más recientemente en Haddadi et al. (2024). Además, con los datos de campañas de retención mostrando un desbalance entre clientes activos y perdidos, los enfoques de preprocesamiento y balanceo de datos son una parte esencial del proceso para una mejor predictibilidad en los modelos predictivos.
Desde el punto de vista de la variable V3: Call center retention campaign data in telecommunications, la necesidad de estos datos de los centros de llamadas ha hecho un modelo más realista basado en la combinación de comportamiento y detalles de transacciones de los clientes, como la frecuencia de las llamadas, la duración de la interacción, el motivo del contacto y los resultados de gestión (Freire et al., 2024). Aunque la evidencia sugiere que se ha realizado una investigación limitada en el contexto de aplicación operativa de tales modelos en sistemas basados en CRM, lo que constituye una importante brecha metodológica para futuras investigaciones (Ribeiro et al., 2024). Como se describe en esta sección, un análisis cienciométrico muestra que los términos “Churn prediction”, “Telecommunication Sector”, “Customer retention” y “Customer churn” están estrechamente agrupados en los clústeres principales, reforzando la relación conceptual positiva entre estas tres variables. Sin embargo, la distancia relativa entre términos como sistema inteligente o CRM, aunque hay un amplio interés que puede aplicarse prácticamente a estas áreas, sugiere que los modelos de predicción aún no han ingresado con éxito al entorno de servicio al cliente (Haddadi et al., 2024; Sana et al., 2024; Liu et al., 2024).
En términos de convergencia, la literatura concuerda en que los enfoques basados en aprendizaje automático
producen predicciones más altas y permiten una inversión de recursos más eficiente para la retención.
En cuanto a las variaciones, ocurren discrepancias en torno a lo siguiente: (i) la preferencia por ciertos algoritmos, donde Random Forest suele dominar, aunque algunos estudios proponen alternativas como Gradient Boosting o redes neuronales profundas. (ii) Respecto a las métricas utilizadas para evaluar el rendimiento, predominan accuracy y AUC, pero se reporta inconsistencia en F1-score o recall. (iii) Niveles de explicabilidad exigidos en el entrenamiento de los modelos, evidenciándose una limitada adopción de técnicas XAI como SHAP o LIME.
Por último, pero no menos importante, esta revisión contribuye a la literatura al señalar una brecha crucial: cómo los resultados de predicción algorítmica necesitan conectarse a estrategias prácticas basadas en datos reales de interacción con clientes (Moradi et al., 2024). Esta integración permitirá la implementación de sistemas inteligentes de retención que no solo predigan qué clientes se irán, sino que también ofrezcan acciones de retención automatizadas y personalizadas en cada perfil del cliente.
Conclusiones y recomedaciones
Conclusión principal
La revisión bibliométrica y el análisis cienciométrico verifican que los modelos de clasificación de aprendizaje automático se han convertido en un método eficiente para predecir la pérdida de clientes basándose en datos de campañas de retención en centros de llamadas de telecomunicaciones.
La literatura actual ilustra un fuerte consenso sobre la capacidad de estos modelos para mejorar el razonamiento estratégico y reducir la pérdida de clientes, pero todavía quedan por abordar los problemas asociados con la interpretabilidad y la incorporación en procesos operativos reales.
Conclusiones específicas
a) Temática
Se cuenta con algoritmos con precisiones que van del 85 al 99 %. En comparación con los enfoques estadísticos clásicos, estos modelos capturan la relación no lineal entre las variables de comportamiento del cliente y los indicadores de retención.
b) Metodológica
El análisis cienciométrico muestra que la investigación sobre la predicción de la pérdida de clientes se lleva a cabo principalmente entre los encuestados ubicados en Islandia, Siria y Australia, cuya mayoría de métodos son cuantitativos y experimentales, utilizando conjuntos de datos públicos junto con métodos de equilibrio de clases como SMOTE o ADASYN.
c) Tendencial
Las tendencias recientes de adopción de modelos híbridos junto con el enfoque de aprendizaje profundo están acompañadas de técnicas de explicabilidad como SHAP y LIME, que intentan la transparencia en la toma de decisiones de los modelos. Este movimiento se dirige hacia algo más allá de los modelos de predicción, hacia sistemas interpretables para la gestión de clientes.
d) Integrativa
La implementación de modelos de predicción con tecnologías CRM y de centros de llamadas aún está en sus inicios. La ausencia de investigación aplicada a partir de prácticas indica una desconexión entre los estudios académicos y la aplicación comercial exitosa.
Limitaciones de la revisión
Cobertura de fuentes
La búsqueda se limitó a artículos académicos publicados en inglés entre 2020 y 2025 de las bases de datos Scopus, IEEE Xplore, ScienceDirect y arXiv. No se tomaron en cuenta los artículos de conferencias, lo que podría haber pasado por alto nueva literatura.
Calidad de los metadatos
El análisis cienciométrico se basa en la calidad de los metadatos bibliográficos exportados de Zotero, lo que puede llevar a sesgos en el conteo de autores, afiliaciones o citas.
Limitaciones técnicas del análisis
Los resultados visuales de Google Colab y los mapas de clústeres, redes de palabras clave y distribución de citas dependen de parámetros de configuración y de la integridad de las etiquetas semánticas, donde estas últimas a menudo pueden influir en la calidad del análisis de los clústeres temáticos.
Carácter no experimental
Con base en la naturaleza como tal, nuestra revisión carece de validación empírica de modelos de predicción y se fundamenta más bien descriptiva y analíticamente en evidencia documental, no en trabajo experimental con datos de clientes.
Futuras líneas de investigación
Vacíos temáticos
Investigar cómo los modelos predictivos pueden integrarse en sistemas CRM y plataformas de centros de llamadas utilizando XAI y análisis en tiempo real de interacciones. También es una idea valiosa investigar el efecto de la predicción algorítmica en la experiencia y satisfacción del cliente.
Necesidades metodológicas
Crear estudios empíricos y ejemplos en la práctica utilizando empresas reales para evaluar la eficacia de los modelos de aprendizaje automático a nivel operativo (rendimiento vs. costos).
Extensiones geográficas
Repetir el estudio en América Latina y África, que tienen menos presencia durante la producción científica, para
investigar el impacto de los factores culturales y de mercado en los patrones de pérdida y retención de clientes.
Perspectiva interdisciplinaria
Integrar el análisis de sentimientos con técnicas de minería de texto en torno a interacciones multicanal como correo electrónico o redes sociales, para aumentar la base de datos predictiva y la precisión del modelo.
Referencias
Aria, M., & Cuccurullo, C. (2016). bibliometrix: Comprehensive Science Mapping Analysis (versión 5.1.1) [Software]. https://CRAN.R-project.org/package=bibliometrix
Bradshaw, A., Bishop, D., & Woodhead, Z. (2017). Systematic Review Protocol. https://osf.io/hyvc4
Chocobar Reyes, E. J., y Barreda Medina, R. F. (2025).
Estructuras metodológicas PICO y PRISMA 2020 en la
elaboración de artículos de revisión sistemática: Lo que todo investigador debe conocer y dominar. Ciencia Latina Revista Científica Multidisciplinar, 9(1), 8525-8543. https://doi.org/10.37811/cl_rcm.v9i1.16491
Donthu, N., Kumar, S., Mukherjee, D., Pandey, N., & Lim, W. M. (2021). How to conduct a bibliometric analysis: An overview and guidelines. Journal of Business Research, 133, 285- 296. https://doi.org/10.1016/j.jbusres.2021.04.070
Freire, D., Santos Mauricio Sanchez, D., Castillo Sequera, J. L., & Fiallo Moncayo, D. (2024). Factors, Predictability, and Explainability of Mobile Telephony Customer Departure in Telecommunications Companies: A Systematic Review of the Literature. IEEE Access, 12, 118968-118980. https://doi.org/10.1109/ACCESS.2024.3443318
Gusenbauer, M., & Haddaway, N. R. (2020). Which academic search systems are suitable for systematic reviews or meta-analyses? Evaluating retrieval qualities of Google Scholar, PubMed, and 26 other resources. Research Synthesis Methods, 11(2), 181-217. https://doi.org/10.1002/jrsm.1378
Haddadi, S. J., Farshidvard, A., Silva, F. D. S., dos Reis, J. C., & da Silva Reis, M. (2024). Customer churn prediction in imbalanced datasets with resampling methods: A comparative study. Expert Systems with Applications, 246, 123086. https://doi.org/10.1016/j.eswa.2023.123086
Kolaski, K., Logan, L. R., & Ioannidis, J. P. A. (2023). Guidance to best tools and practices for systematic reviews. Acta Anaesthesiologica Scandinavica, 67(9), 1148-1177. https://doi.org/10.1111/aas.14295
Liu, X., Xia, G., Zhang, X., Ma, W., & Yu, C. (2024). Customer churn prediction model based on hybrid neural networks. Scientific Reports, 14, 30707. https://doi.org/10.1038/s41598-024-79603-9
Moradi, B., Khalaj, M., Herat, A. T., Darigh, A., & Yamcholo, A.T. (2024). A swarm intelligence-based ensemble learning model for optimizing customer churn prediction in the telecommunications sector. AIMS Mathematics, 9(2), 2781-2807. https://doi.org/10.3934/math.2024138
Ouf, S., Mahmoud, K. T., & Abdel-Fattah, M. A. (2024). A proposed hybrid framework to improve the accuracy of customer churn prediction in telecom industry. Journal of Big Data, 11, 70. https://doi.org/10.1186/s40537-024-00922-9
Ouzzani, M., Hammady, H., Fedorowicz, Z., & Elmagarmid, A. (2016). Rayyan—a web and mobile app for systematic reviews. Systematic Reviews, 5, 210. https://doi.org/10.1186/s13643-016-0384-4
Page, M. J., McKenzie, J. E., Bossuyt, P. M., Boutron, I.,
Hoffmann, T. C., Mulrow, C. D., Shamseer, L., Tetzlaff,
J. M., Akl, E. A., Brennan, S. E., Chou, R., Glanville, J.,
Grimshaw, J. M., Hróbjartsson, A., Lalu, M. M., Li, T., Loder,
E. W., Mayo-Wilson, E., McDonald, S., Moher, D. (2021). Declaración PRISMA 2020: una guía actualizada para la publicación de revisiones sistemáticas. Revista Española de Cardiología, 74(9), 790-799. https://doi.org/10.1016/j.recesp.2021.06.016
Reddy, S. A., Gowtham, M., Tripathy, K. P., & Srinivas, M. (2025). Enhanced Telecom Customer Churn Prediction Using Machine Learning and Deep Learning Models [conferencia]. 2025 International Conference on Artificial Intelligence and Data Engineering (AIDE), Nitte, India. https://ieeexplore.ieee.org/document/10987431
Ribeiro, H., Barbosa, B., Moreira, A. C., & Rodrigues, R. G. (2024). Determinants of churn in telecommunication services: a systematic literature review. Management Review Quarterly, 74, 1327-1364. https://doi.org/10.1007/s11301-023-00335-7
Salgado-García, J. A., Terán-Bustamante, A., & Velázquez- Salazar, M. (2025). Thematic mapping of artificial intelligence in management: A bibliometric approach using co-word analysis (2015–2024). Iberoamerican Journal of Science Measurement and Communication, 5(3), 1-11. https://doi.org/10.47909/ijsmc.205
Sana, J. K., Rahman, M. S., & Rahman, M. S. (2024). Privacy- Preserving Customer Churn Prediction Model in the Context of Telecommunication Industry. arXiv:2411.01447v1 [cs. LG]. https://doi.org/10.48550/arXiv.2411.01447
Snyder, H. (2019). Literature review as a research methodology: An overview and guidelines. Journal of Business Research, 104, 333-339. https://doi.org/10.1016/j.jbusres.2019.07.039
Subramanian, D., Ajitha, A., & Maidin, S. S. (2025). Unveiling Hybrid Model with Naive Bayes, Deep Learning, Logistic Regression for Predicting Customer Churn and Boost Retention. Journal of Applied Data Sciences, 6(2), 1379- 1391. https://doi.org/10.47738/jads.v6i2.675
Zdanavičiūtė, M., Juozaitienė, R., & Krilavičius, T. (2022). Telecommunication customer churn prediction using machine learning methods [conferencia]. IVUS 2022: 27th International Conference on Information Technology, Kaunas, Lituania. https://ceur-ws.org/Vol-3611/paper15.pdf
Fuentes de financiamiento
La investigación fue realizada con recursos propios.
Conflictos de interés
El autor declara no tener conflictos de interés.
Correspondencia:
Merjory Grisell Candela Sevilla
E-mail: merjory_candela@usmp.pe
